One of the two fundamental concepts and equally important term in AI world is ‘Variance’. Although, we often underestimate this concept and involve ourselves more into improving the accuracy of the model. This ultimately degrades the overall nature of the model. Let’s discuss in more detail about Variance.

What is Variance in AI or ML?
Before we begin to understand the effects of Variance in AI/ML models, let’s understand what is the core concept of Variance.
Variance is an statistical term, a part of ‘measure of central tendency’ metrics, measures the distance of each data point in a dataset from its mean (average) and from every other number in the dataset. Basically, it reflects how spread out individual data points are. In statistics, it is denoted by sima squared (σ2). The practical example of implementation of Variance metrics in Finance sector is measuring the ‘volatility’ and ‘market security’ of financial instruments.
Variance in machine learning models measures the randomness of predicted value from the actual value. In laymen’s terms, it measures the model’s sensitivity to fluctuations in the data i.e. the noise. Similar to Bias, a machine learning or artificial intelligence model can also have high and low variance.
High Variance:

A model with high variance learns everything provided to it and performs very well with the training dataset, but fails to deliver same performance with test dataset. This is also termed as ‘overfitting’. The cause of such situation arise when we allow model to perform too much learning from the training dataset or the dataset itself has too much noise. Noise, here, means irrelevant details which are not required for predicting the output.
Example:
If you take a linear dataset, i.e. the data which has visible trend when plotted on scatter graph, and try to fit your model by tuning hyperparameters such that the model accurately predicts the label value or dependent variable in training dataset. This results in training dataset error to be zero (0). But in turn, the model has been exposed to overfitting, and when any new dataset or test dataset is used to predict the labels, it will result in extremly high test dataset error.
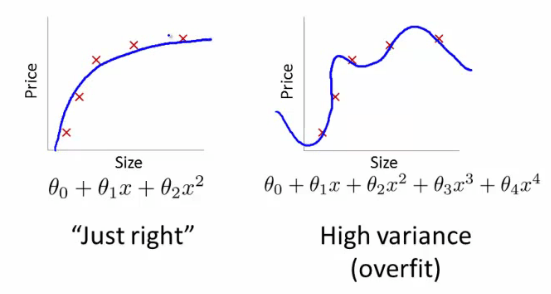
These are the signs of machine learning model with high variance:
- Noise in dataset i.e. irrelevant details have been captured
- Overfitting i.e. capturing or nearing all the data points in the visualization
- Complexity, i.e. tuning all the hyperparameters for perfect accuracy
- Forcing the data points together
Bias and Variance goes hand in hand for any AI/ML model. Here is the article that can help you understand more about Bias.
Also, don’t forget to subscribe newsletter for updates on new articles and upcoming exciting sections.
One Reply to “Variance in AI / ML: A practical understanding”